
Tout a commencé par un message d’une seule ligne provenant d’une équipe financière un mardi après-midi : une poignée de clients avaient été facturés deux fois ce jour-là, et l’un d’entre eux contestait un prélèvement en double auprès de sa banque.
Je suis allé directement au contrôle, m’attendant à trouver quelque chose de cassé. Au lieu de cela, tout semblait sain : d’après les propres enregistrements du système, chaque commande avait été payée exactement une fois. Il a fallu à l’équipe un mois d’analyse des incidents de production pour combler l’écart entre un tableau de bord indiquant « tout va bien » et un client facturé deux fois.
Depuis, j’ai constaté ce type de défaillance sur plusieurs systèmes de paiement, certains traitant des centaines de milliers de transactions par jour. Ce qui suit est un composite et ne décrit aucun système ou organisation en particulier. Les numéros, les horaires et les détails d’identification ont été modifiés pour empêcher tout élément exclusif d’entrer.
La nouvelle tentative qui a facturé deux fois
Un client a cliqué sur Payer ; le service de commande a appelé le service de paiement, qui a appelé le prestataire externe. Le fournisseur a facturé 200 $ sur la carte et a enregistré un succès de son côté.
La seule chose qui n’a pas fonctionné, c’est le timing. Le fournisseur était sous charge et a mis un peu plus de 3 secondes pour répondre. Le client a abandonné au bout de 2 secondes, un défaut hérité des appels de service internes et jamais réglé pour les paiements. Du côté de l’appelant, l’appel avait tout simplement échoué et rien n’était donc marqué comme payant.
La logique de nouvelle tentative a fait ce pour quoi elle a été conçue et a renvoyé la demande. Le fournisseur a vu ce qui ressemblait à une nouvelle facture et a pris l’argent une seconde fois. La base de données a enregistré un paiement : la nouvelle tentative. La première accusation ne figurait que dans les dossiers du fournisseur, invisible pour nous jusqu’à ce que les plaintes arrivent.
Violetta Pidvolotska
Les doublons ont été remboursés en quelques heures, avant que le litige ne se transforme en rétrofacturation. Il a fallu beaucoup plus de temps pour comprendre ce qui avait réellement échoué.
Plus tard, nous avons élargi le délai d’attente bien au-delà des réponses saines les plus lentes du fournisseur, mais tant qu’une nouvelle tentative peut déclencher une deuxième charge, un délai d’attente plus long ne fait que rendre la double charge plus rare.
La véritable erreur était plus ancienne que la limite elle-même. Le système a été informé qu’un délai d’attente signifie un échec.
Le troisième état
Nous avons tendance à considérer un appel réseau comme ayant deux résultats : il a fonctionné ou il n’a pas fonctionné. Un temps mort est le troisième. La demande n’est peut-être jamais arrivée. Il a peut-être fait son travail et perdu la réponse au retour. C’est ce qui nous a mordu. Ou il se peut qu’il soit toujours en cours d’exécution. Du côté de l’appelant, vous ne pouvez pas dire lequel.
Le code a rarement un chemin séparé pour « inconnu ». Il est regroupé avec l’échec et le chemin d’échec réessaye. Lorsque la demande déplace de l’argent, c’est ainsi que vous facturez quelqu’un deux fois.
Un service lent se traduit par des temps de réponse croissants, un service peu fiable par des erreurs. Une double facturation s’avère être un succès, et personne ne le remarque jusqu’à ce qu’un client le fasse.
Les délais d’attente, dont j’ai déjà parlé, transforment les blocages silencieux en échecs visibles. Et les échecs visibles sont retentés, c’est ainsi que nous sommes arrivés à l’idempotence.
« Exactement une fois » est utilisé comme s’il s’agissait d’un paramètre que vous pouviez activer. Vous ne pouvez pas promettre une livraison unique sur un réseau peu fiable, comme l’explique Tyler Treat. Ce que vous pouvez promettre, ce sont des effets exactement une fois : la demande peut arriver deux fois, tandis que la facturation n’a lieu qu’une seule fois.
Mon premier réflexe a été d’arrêter de réessayer automatiquement les paiements et cela m’a aidé. Mais nous ne pouvons pas désactiver chaque nouvelle tentative : le client actualise la page ou une politique de nouvelle tentative quelque part dans l’infrastructure est renvoyée d’elle-même.
Les hypothèses sous la clé
Le remède standard est une clé d’idempotence : l’appelant attache une valeur unique à une tentative d’opération et envoie la même valeur à chaque nouvelle tentative. Une nouvelle clé est traitée et son résultat est stocké ; un résultat familier récupère le résultat stocké, donc la nouvelle tentative n’a aucun effet supplémentaire. La présentation pas à pas de Brandur Leach des clés d’idempotence de type Stripe dans Postgres présente le modèle bout à bout.
La clé a été expédiée et les doublons ont été arrêtés. Mais nous nous sommes détendus trop tôt. La clé s’est avérée être la partie la plus facile.
Une clé comme celle-ci repose sur quatre hypothèses. Depuis, je les ai transformés en une liste de contrôle que j’appelle le test des quatre hypothèses :
- Réclamer. Pour réclamer une clé, il suffit de vérifier d’abord qu’elle est gratuite.
- Intention. La même clé porte toujours la même intention.
- Mémoire. Tout ce dont une clé se souvient peut être rejoué en toute sécurité.
- Limite. Rien derrière la clé n’échappe à votre contrôle.
Au cours du mois suivant, tous les quatre se sont cassés : la course lors d’un test de charge, les trois autres en production.
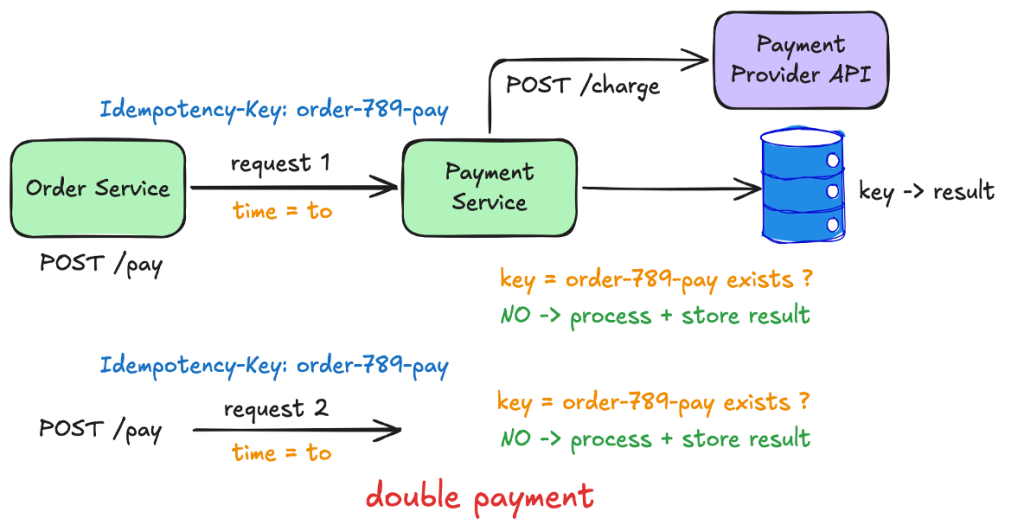
Deux requêtes, même milliseconde
Lors d’un test de charge, deux requêtes avec la même clé sont arrivées dans la même milliseconde. Chacun vérifia la clé ; ni l’un ni l’autre ne l’ont trouvé et tous deux ont commencé le traitement.
Violetta Pidvolotska
« Vérifiez si la clé existe, puis écrivez-la » est une course comme une autre et elle a brisé l’hypothèse de la revendication. Nous l’avons corrigé en inversant l’ordre : nous écrivons maintenant la clé est le chèque. Chaque requête l’écrit comme « démarrée » et la base de données ne laisse gagner qu’une seule réclamation. La sauvegarde :
-- Try to claim the key; the UNIQUE index lets only one caller win.
INSERT INTO operations (idempotency_key, state) VALUES (:key, 'started')
ON CONFLICT (idempotency_key) DO NOTHING;L’insertion touche une ligne ou aucune, et ce nombre vous indique sur quel chemin vous vous trouvez. Une ligne signifie que vous avez gagné : appelez le fournisseur, puis marquez la ligne comme « terminée » et enregistrez la réponse. Aucun signifie que vous avez perdu : lisez la ligne et renvoyez sa réponse enregistrée ou demandez à l’appelant de réessayer plus tard si elle est toujours « démarrée ».
Il est facile de se tromper sur un détail : validez la réclamation avant que l’appel du fournisseur ne soit émis. Sinon, un crash le fait reculer et efface le seul enregistrement indiquant qu’une charge peut être en vol.
Le cas le plus difficile est celui d’une requête gagnante qui plante en cours de charge : sa clé est bloquée sur « démarré » et chaque nouvelle tentative est invitée à attendre une réponse qui ne viendra jamais. Une réclamation bloquée est à nouveau la même inconnue : une fois qu’elle est restée « démarrée » plus longtemps que n’importe quel appel sain ne pourrait prendre, demandez au fournisseur ce qui s’est réellement passé avant que quelqu’un ne facture à nouveau.
Même clé, demande différente
Le deuxième écart est apparu une semaine après le début de la production et a brisé l’hypothèse d’intention : un appelant a réutilisé une clé pour deux demandes différentes, 200 $ et 500 $, et le système a renvoyé la réponse stockée de la première demande sans remarquer que le montant avait changé.
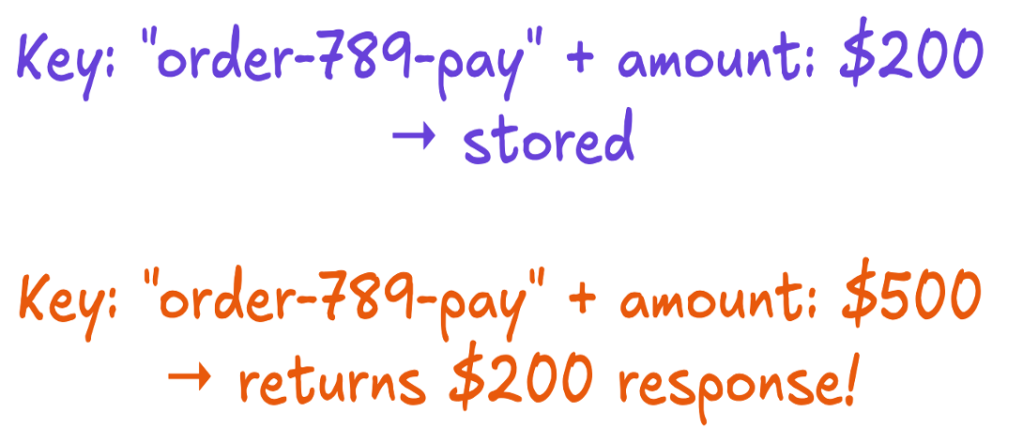
Violetta Pidvolotska
Nous avons corrigé ce problème en stockant une empreinte digitale du contenu de la requête à côté de la clé, sur le même insert, afin qu’une requête qui perd la course aux réclamations puisse toujours comparer son empreinte digitale avec celle du gagnant. Si les empreintes digitales correspondent, c’est une véritable nouvelle tentative. Dans le cas contraire, la clé a été réutilisée pour une opération différente et nous la rejetons.
Ce correctif a rapidement rejeté une nouvelle tentative valide. Nous avions pris les empreintes digitales de l’intégralité de la demande, y compris un horodatage qui changeait entre les tentatives et les champs arrivés dans un ordre différent, de sorte que les empreintes digitales ne correspondaient pas.
Une empreinte digitale doit capturer ce que signifie une requête plutôt que la façon dont ses octets sont organisés. Hachez une liste de champs d’activité triés sur le volet et vous risquez une collision silencieuse : le champ que personne n’a pensé à ajouter permet de faire correspondre deux demandes différentes. Hachez toute la requête moins le bruit connu comme les horodatages et l’échec est fort à la place : un champ volatile manqué rejette une nouvelle tentative valide. Nous avons choisi fort, la solution se résumait à deux lignes :
intent = drop_fields(request.json, volatile={"client_ts", "trace_id"}) # strip known noise only
fingerprint = sha256(canonical_json(intent)) # canonical form: keys sorted, numbers and spacing normalizedMême « canonique » cache des décisions. La RFC 8785 les identifie, mais elle fait passer chaque nombre via un double IEEE 754, ce qui perd en précision sur les grandes valeurs, de sorte que les montants en argent sont plus sûrs sous forme de chaînes ou de centimes entiers. Modifiez la forme canonique et chaque empreinte digitale stockée ne correspond plus, nous la versionnons donc et stockons la version à côté de l’empreinte digitale.
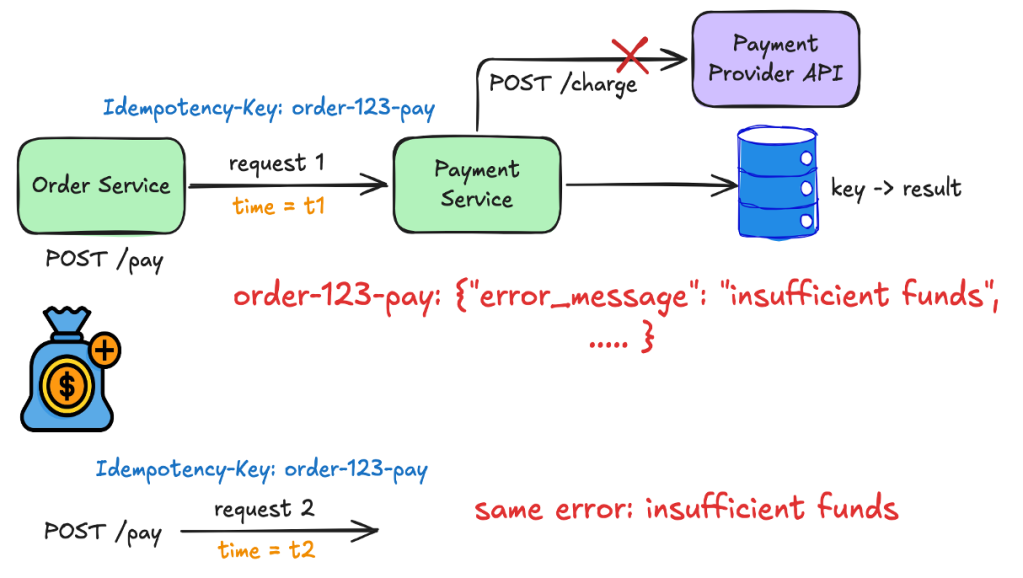
L’erreur que nous avons mise en cache
La troisième lacune est survenue grâce au support : un client a rencontré un problème de fonds insuffisants, a ajouté de l’argent, a réessayé avec la même clé et a récupéré l’ancien « fonds insuffisant ». Le fournisseur n’a jamais été interrogé. Le système avait mis en cache chaque réponse, y compris les refus, de sorte que l’échec restait fidèle à la clé.
Violetta Pidvolotska
Cela a forcé la question derrière l’hypothèse de la mémoire : qu’est-ce qu’une clé est autorisée à retenir ? La règle sur laquelle nous avons atterri : mettre en cache uniquement le succès.
Un léger refus ou une erreur de validation annule la réclamation : la ligne redevient réclamable, l’empreinte digitale est conservée. La tentative suivante le récupère avec une mise à jour qu’une seule nouvelle tentative peut gagner et le client qui ajoute de l’argent obtient une tentative en direct au lieu d’une rediffusion. Les refus définitifs sont l’exception : une réponse concernant le vol d’une carte est définitive et cette réclamation reste close.
En cas d’expiration du délai, nous ne savons pas si la charge a été facturée. Nous demandons donc au fournisseur si la charge a déjà été facturée et nous agissons en fonction de la réponse.
Où la garantie expire
Les trois premiers écarts concernaient des points finaux sous le contrôle de l’équipe. Le quatrième est apparu lors du rapprochement : un débit sur le relevé d’un ancien fournisseur sans aucun enregistrement interne correspondant. Ce fournisseur ne disposait pas de clés d’idempotence et la garantie avait atteint ses limites. Nous ne pouvions pas faire en sorte qu’il soit sécuritaire d’appeler deux fois.
Nous nous sommes approchés le plus possible : un enregistrement en attente avant l’appel, une vérification de l’état avant de réessayer, un rapprochement pour récupérer et rembourser tout ce qui passe. Il reste une fenêtre là où l’accusation a atterri et nos archives ne le savent pas encore. Nous avons continué à réduire cette fenêtre, mais nous n’avons jamais réussi à la fermer.
La base de données qui contient les clés impose une décision qui lui est propre : lorsqu’elle est en panne, soit vous arrêtez d’accepter les paiements, soit vous les acceptez sans protection. Ce choix est une décision professionnelle. Pour une écriture à faibles enjeux, nettoyer un doublon rare peut coûter moins cher que refuser des clients. Un paiement n’est pas un faible enjeu, nous échouons donc et cessons d’accepter les paiements jusqu’à ce que le magasin soit de retour : une vente perdue que nous pouvons récupérer, et nous venions de passer un mois à apprendre ce que coûtent les doublons.
Questions que je pose dans les revues de conception
Pour tout ce qui stocke ou modifie des données, je pose trois questions :
- Que se passe-t-il si cela s’exécute deux fois ? Demandez-le à voix haute pour chaque écriture.
- Pouvons-nous prouver la réponse ? Exécutez-le deux fois en tests, en séquence et en parallèle ; la deuxième manche ne devrait rien changer.
- Où se trouve la vérité lorsque les systèmes sont en désaccord ? Pour les paiements, c’est le fournisseur, car ses dossiers indiquent si l’argent a réellement été transféré. Décidez quelle réponse l’emporte avant qu’un incident ne le fasse.
La clé est une bonne idée et, dans tout ce qui déplace de l’argent, une idée nécessaire. Ce n’est tout simplement pas une garantie. La garantie est la conception qui l’entoure : une revendication qui ne peut pas faire de course, une intention confirmée par l’empreinte digitale, une mémoire qui ne conserve que ce qui peut être rejoué en toute sécurité et une limite que vous avez tracée à l’avance. C’est le test des quatre hypothèses. Chaque hypothèse est finalement testée : vous le faites au moment de la conception ou la production le fait pour vous.
Cet article est publié dans le cadre du Foundry Expert Contributor Network.
Voulez-vous nous rejoindre ?





